LARA - Long Context LLMs VS RAG
- LARA - Benchmarking Retrieval-Augmented Generation and Long-Context LLMs - No Silver Bullet for LC or RAG Routing Link
- ICML 2025 Poster
- Alibaba group
요약
- Long context LLM의 등장... 과연 RAG는 유효한 전략인가?
- LARA - Long context LLM과 RAG 비교에 적합한 벤치마크
- 4개의 실용적인 QA 카테고리
- 3가지 종류의 긴 텍스트 (소설, 논문, 금융 관련 보고서)
- 실험 결과, THERE IS NO SILVER BULLET
LARA를 만든 원칙
- Context Length를 모델의 최대 인풋 길이에 맞게 최대한 길게 넣어줘야 한다.
- Infinte-bench라는게 있었는데, 평균 길이가 128k를 넘어가서 내용 절반씩 잘린채로 들어갔다.
우리가 잘 잘라서 넣어보니깐 Qwen-2.5-7B가 안자르고 넣은 gpt-4o를 이기더라.
- Infinte-bench라는게 있었는데, 평균 길이가 128k를 넘어가서 내용 절반씩 잘린채로 들어갔다.
- Context는 원래부터 긴 문서여야 한다.
- Qasper는 고작 평균 4912 토큰이다.
- LLM의 내부 지식으로는 답변할 수 없어야 한다. (Data Leakage)
- NarrativeQA는 평균 84,770토큰이지만 Gemini 1.5 Pro는 거의 100% 정확도를 달성한다.
- 정해진 답이 있어야 한다 (정확한 평가를 위하여)
- 기존에는 생성 태스크에 전혀 적합하지 않은 F1이나 EM을 쓴다.
- real-world LLM 시나리오에서 나올법한 질문이어야 한다.
LARA를 만든 법
소설, 논문, 금융 관련 보고서 (분기 보고서, 연간 보고서 등)을 모았다.
Data Leakage를 막기 위해서 entity replacement (고유 명사 등을 대체)를 수행했다.
먼저 seed question과 answer를 만든 후에 이것을 few-shot으로 해서 gpt-4o에게 새로운 QA 페어를 생성하도록 했다. 랜덤으로 뽑았을 때 퀄리티가 괜찮을 때까지 프롬프트를 깎았다.
질문을 만들때는 10k 정도로 잘라서 gpt-4o에 넣었다. 특히 comparison 만들때는 더 작게 만들어서 랜덤으로 두 개를 골랐다.
LARA의 4가지 태스크
1. Location Task
Needle in a haystack과 비슷한데, 뜻만 같다면 paraphrasing이 허용된다.
ex) 경희대 교육과정 전체를 주며, '컴퓨터공학과 단일전공 졸업학점은?'
2. Reasoning Task
논리적인 사고나 계산을 요구하는 태스크.
3. Comparison Task
긴 context 내의 여러 파트에서 정보를 수집해서, 각각의 정보를 비교한 후 최종 결론에 다다를 수 있는가?
4. Hallucination Detection
Context 내에 없는 정보에 관해서는 답변을 거부하는 능력.
메트릭
gpt-4o가 채점했다. LARA에는 정해진 답 뿐이기 때문에 채점이 용이하다.
그리고 gpt-4o가 잘했는지 사람이 몇 개 채점해서 correlation을 구해봤다.
실험
베이스라인
- 7개의 오픈소스 모델, 4개의 closed-source 모델 사용
- RAG 세팅
- 600 토큰 chunk, 100 토큰 overlap
- 문서 당 top-5개의 chunk를 사용
- GTE-large-en-v1.5 임베딩 사용
- Hybrid Retrieval (w. BM25) 사용
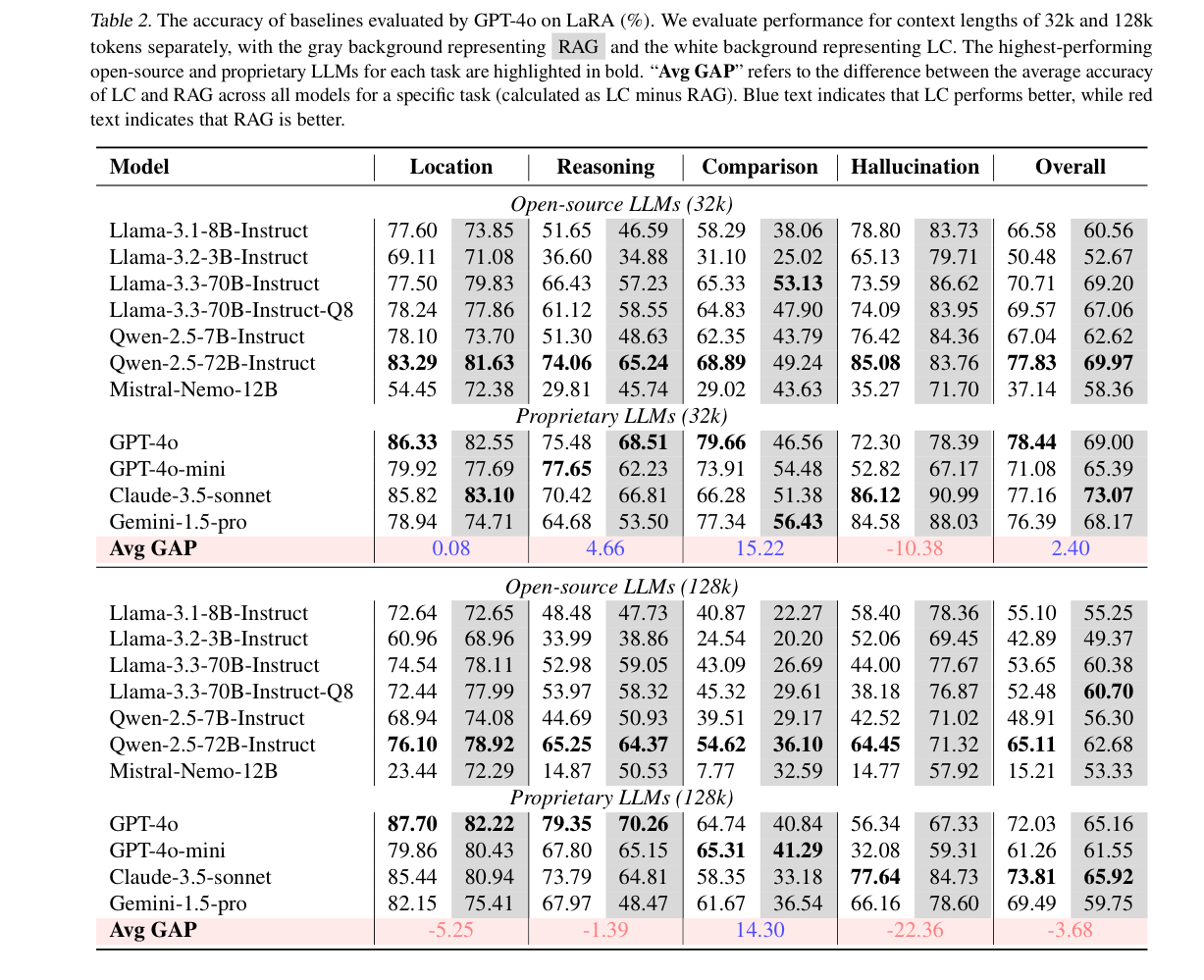
Avg GAP은 LC - RAG입니다. (음수면 RAG가 더 좋았다)
결과 해석
-
32k 오픈소스 모델 - LC가 RAG보다 좋았다.
-
128k 오픈소스 모델 - RAG가 LC보다 좋았다.
-
closed-source 모델 - LC가 RAG보다 좋았다.
-
128k에서 최고 점수 3개는 LC, 최소 점수 3개 또한 LC
- 작은 사이즈의 오픈소스 모델에서는 LC가 오히려 안좋다.
-
큰 모델 >>>> 작은 모델
-
Comparison은 LC가, Hallucination Detection은 RAG가 더 잘했다.
-
Location과 Reasoning은 차이도 크지 않고, 모델이나 context length에 따라 제각각이었다.
-
Context 종류에 따라 살펴보니, 소설의 경우 RAG와 LC의 차이가 크지 않았다. (다른 것들에 비해)
- LC는 잘 구조화된 텍스트에 유용하다 (논문이나 금융 보고서)
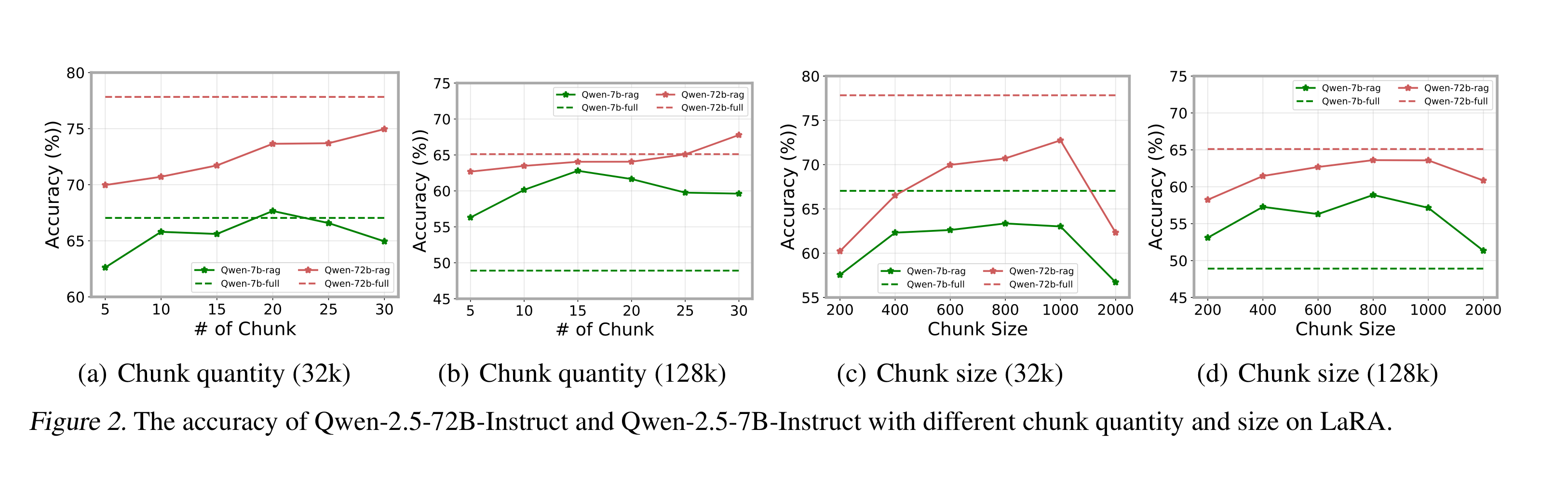
- 72B에서는 chunk 양을 늘릴수록 더 높아지지만, 7B에서는 떨어지는 경향이 있었다.
- chunk의 사이즈가 너무 높아지면 검색이 잘 안되기에 성능이 떨어지는 구간이 생겼다 (모델 크기 상관 X)
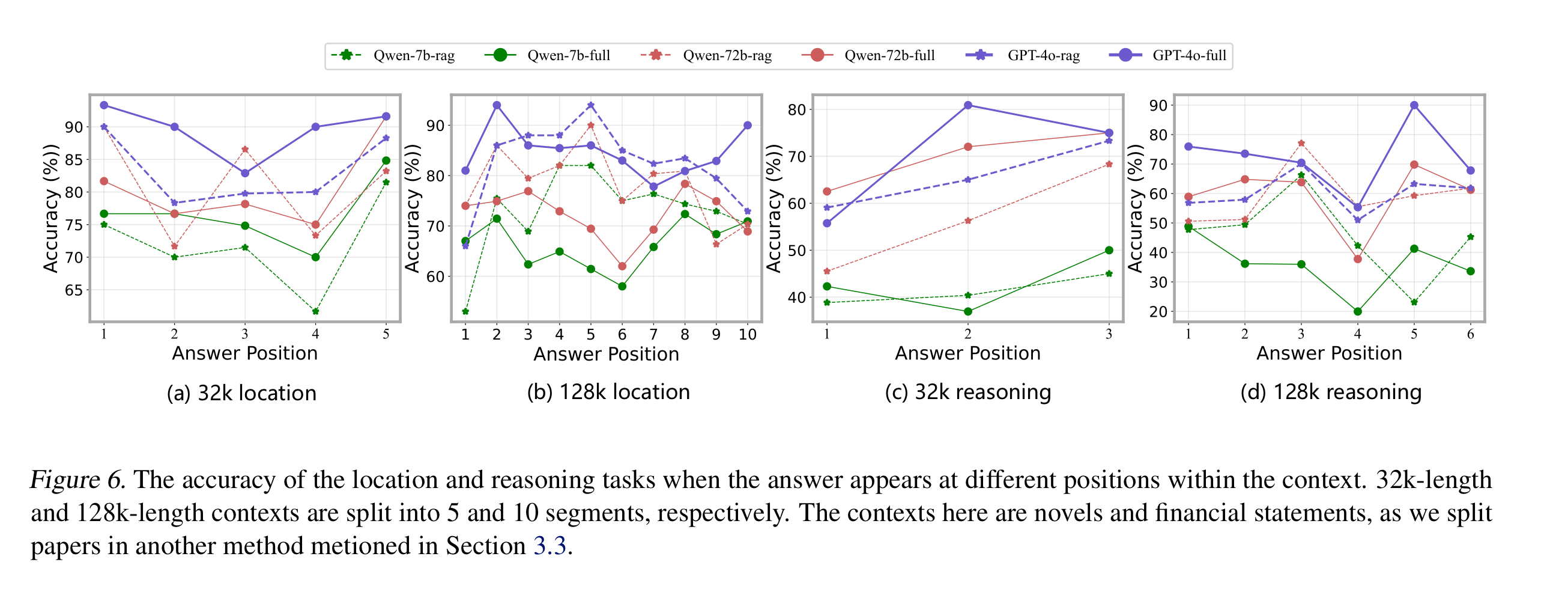
- LC에서는 Lost in the Middle 현상이 관찰되었고, RAG에서는 그런 현상이 관측되지 않았다.
결론
- RAG vs LC => THERE IS NO SILVER BULLET
- 상황에 알맞은 전략을 택하는 것이 중요하다!
- 특히나 비용까지 고려하면 RAG의 손을 들어줄 때가 더 많아지지 않을까?